Last week the Franklin D. Roosevelt Presidential Library and Museum announced online availability of the Franklin D. Roosevelt Master Speech File. The collection contains 1,592 documents, totaling 46,000 pages, spanning the years 1898-1945. This is an essential set of primary sources, and given availability in digital form they become amenable to research questions that can be extended via computational means.
That being said, digital collection access points are generally not designed to support users interested in working with collections at scale. Getting access to sources like these beyond the item level poses familiar challenges. The route across these challenges is replete with twisty little passages.
In light of these challenge I’ve strung together a sample bulk data gathering and transformation workflow using the FDR Master Speech File as a use case.
Steps are as follows:
1. compile a list of collection item links
2. use that list to instruct wget which content it should download
3. specify wget limitations so it doesn’t burden source data server
4. mass append file extensions to items when they are missing them
5. mass remove the first page of every file (reasons will become clear)
6. extract OCR data from every PDF file
7. create plain text files with OCR data
The end product of this workflow is a plain text corpus derived from the FDR Master Speech File. Components of the workflow should scale to working with other data sources.
Tools
xcode – developer tools
Homebrew – ‘package manager’ makes it easier for you to install tools
wget – command line tool for downloading websites, or specific files in them
Firefox – popular web browser
Copy All Links – Firefox add-on, that lets you copy links on a page
PDFtk Server – command line PDF manipulation tool
PDFtoText – command line tool for converting PDF to plain text
Challenge 1: Examining the data source
All content in the FDR Speech Master File is listed on a single page.
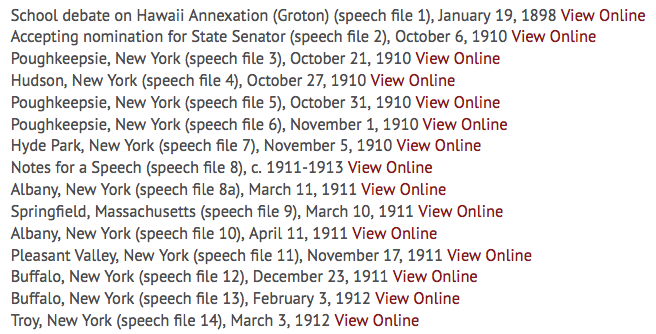
By right clicking on a ‘View Online link’ and selecting, ‘Inspect Element’ or ‘Inspect’, it becomes apparent that each link connects directly to the desired item. This is an important distinction, as the link could have gone to a record about that item, in which case the task of compiling the list of item URLs would have been more difficult.
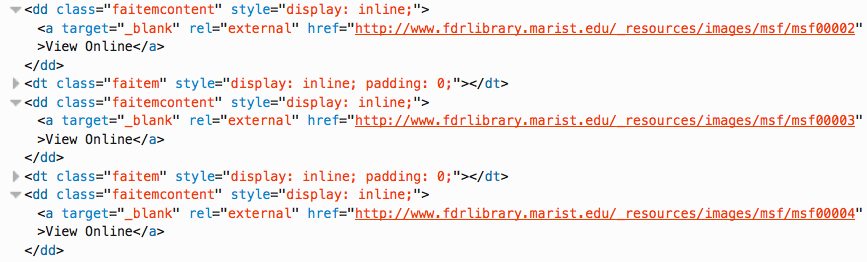
Typically we would proceed to use something like wget to download all files of a given type (e.g. PDFs, JPEGs) from the FDR Speech Master File page but we run into a couple of problems. These links have no file extensions so we can’t readily instruct wget to download them in that manner. A second approach might entail, mirroring the website as a whole or perhaps certain sections of the website, but that is really overkill and would take a very long time if you did it responsibly. Instead, we’ll pursue a targeted strategy.
Challenge 2: Getting the data
During this step we build a list of collection item URLs and use wget to download them. We download responsibly by limiting the speed of downloads and staggering our requests to source data collection servers.
Copy all links on the FDR Master Speech File page.
– Right click anywhere on the FDR Master Speech File page
– Select ‘Copy All Links’ > ‘Current Tab’ > ‘All Links’
Paste those links into a text editor
– Delete links that do not connect to collection items
– Save file to desktop as fdrspeechlist.txt
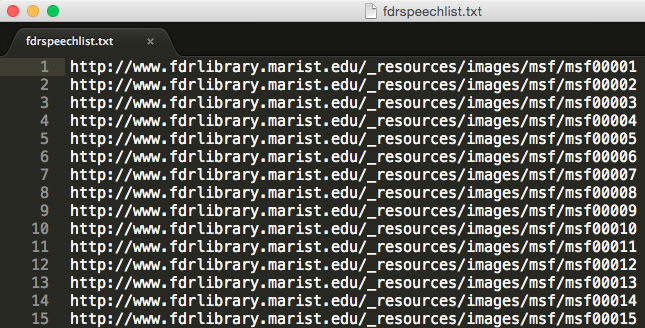
Now that we have the list of URLs we’ll use wget to begin downloading each collection item
– Create a folder on your desktop to contain the FDR speeches
– Open Terminal
– Navigate to the folder that will hold the FDR speeches e.g. cd/Desktop/fdrspeeches
Download each file in the list with download rate and item request limitations
wget -w 12 --limit-rate=20k -i /yourpath/fdrspeechlist.txt-w 12 : wait 12 seconds between each item request
–limit-rate=20k : limit download rate to 20k
-i /yourpath/fdrspeechlist.txt : give wget the list of URLs you created
This will take quite awhile. Time to go on a day trip. Possibly an overnight trip.
Challenge 3: Shaping Data
When the data finishes downloading, you’ll end up with something like this.
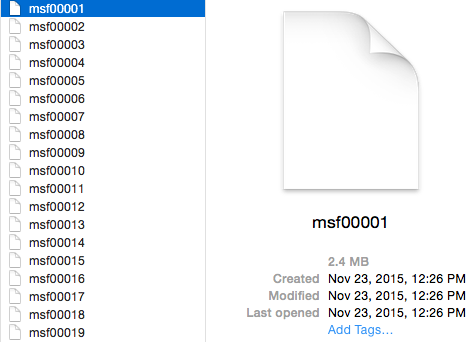
Yikes, no file extensions. What mysteries do they hold? Only double clicks will tell…
We quickly see that the files open in common PDF viewer software. Logic leads us to PDF file format determination. In order to extract plain text from these documents we need to append the PDF file extension to every file. Given that there are many hundreds of files we issue a command from Terminal to do this for us.
– Open Terminal
– Navigate to the folder that holds the FDR speeches e.g. cd/Desktop/fdrspeeches
Append .pdf to every file in a directory
find . -type f -exec mv '{}' '{}'.pdf \;As you review the documents in the collection, you notice that each document is prefaced by a cover sheet.

Sometimes a scan of the physical folder that contains the documents is included as well.

Relative to the target document, arguments can be made for the importance of both pages. The cover sheet provides metadata describing the item in question as does the image of the physical folder. They help to establish the provenance and context of the item. However, if your aim is to generate a corpus readily amenable to some form of text analysis they should be removed as they introduce text data that is about rather than representative of FDR’s speech.
– Open Terminal
– Navigate to the FDR speeches folder, e.g. cd/Desktop/fdrspeeches/
Remove the first page from every PDF file, create a trimmed speech file
for msf in *msf*.pdf;
do
pdftk ${msf} cat 2-end output trimmedspeech_${msf/msf/msf};
done
Efforts in this area will need to be iterative. Some items in the collection contain a cover page and a physical folder image page. Some do not. So basically you are looking at modifying this command to remove 1 or 2 pages depending on the item.
Challenge 5: Extracting Data
Once you finish getting your data into shape its time to extract the OCR data from the pdf files to create your plain text files.
– Open Terminal
– Navigate to the FDR speeches folder, e.g. cd/Desktop/fdrspeeches/
Make a trimmedspeeches folder
mkdir trimmedspeechesMove trimmed speeches to the trimmedspeeches folder (this will an issue an error, but the command works)
mv *trimmed* trimmedspeechesNavigate to the trimmedspeeches folder
cd trimmedspeechesExtract OCR data from every PDF file to create plain text files
for file in *.pdf; do pdftotext "$file" "$file.txt"; doneAt the end of processing, open your files to review.

Step 6: Steps forward
Whew. You’ve reached the end of this road, but another fork presents itself.
As with any project of this kind, OCR quality is highly variable. For the FDR speeches that are type-written the fidelity of the plain text file to the image of the page is often fairly accurate. For hand written annotations on those documents, or purely hand written documents the OCR data used to generate the plain text files are not usable. After a bit of sleuthing it could be the case that there are coherent sections of the overall corpus that tend to be typewritten, at which point a researcher could decide to focus on those areas. Given the depth of the collection, focusing on components of it in lieu of the whole could be intellectually sound. Decisions as to whether or not the remaining portion of the corpus merits hand or crowd transcription is a determination best left in the hands of the researcher querying the collection or the institution that maintains the collection.
While this post focused on the FDR Master Speech File, components of the workflow should scale to helping you navigate the twisty little passages of other data sources. Best of luck!