Text analysis projects share in common 3 challenges. First, data of interest must be found. Second, data must be gettable. Third, if it’s not already formed according to wildest dreams, ways must be known of getting data into a state that they are readily usable with desired methods and tools. While surmounting these challenges are typically not a favored part of the process, more experienced Digital Humanists often have programmatic means of getting data and transforming it in such a way that it suits their needs. These means are not inaccessible to beginners but the path from DH interest to DH exploration is sometimes better wended via a route that poses the least resistance. In what follows, I will describe a method that kludges together a couple of different easy to use tools to download web pages en masse, remove markup, and convert them to .txt.
What you need
Firefox
DownThemAll! Tools – Firefox extension for bulk downloading content from the web
Terminal – OS X command line interpreter
Textutil – command line text utility
Use Case – British Women Romantic Poets, 1789-1832
British Women Romantic Poets, 1789-1832 is a wonderful collection of 169 texts, digitized and encoded by UC Davis General Library. From a temporal and thematic standpoint this collection has a measure of cohesion that lends itself well to text analysis. Accordingly, you’d like to begin exploring the data but first you need to get the data and move it into a state where it is usable.
Challenge 1: Getting data
Examination of the access point indicates that item by item interaction is privileged with no clearly marked mechanism for downloading content.

We could right click and save each HTML link but who has time for that?
We get around this through utilization of DownThemAll! Tools.
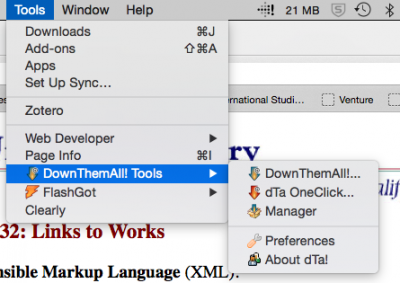
– Open Firefox
– Open DownThemAll! Tools by following this path in the Tools menu: Tools > DownThemAll! Tools > DownThemAll
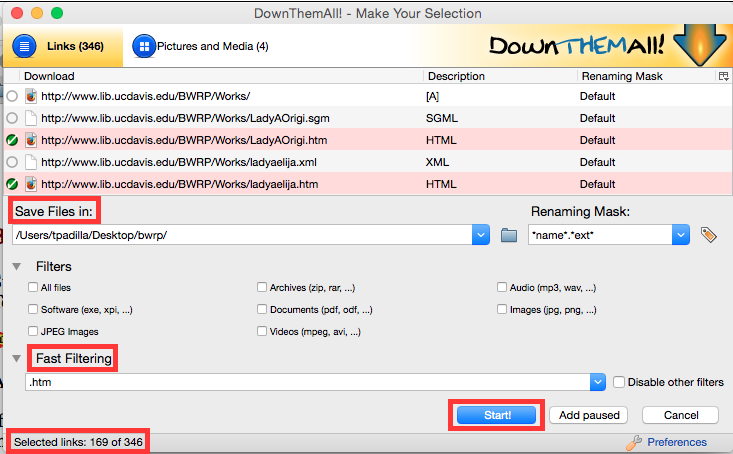
You will then be presented with a window that displays 346 available links on the British Women Romantic Poets page. Of those 346, 169 link to a .htm (precursor to .html) version of a text.
In the DownThemAll window designate a folder to save the 169 .htm files in. Using fast filtering, designate .htm as a filter for the links. You should now see .htm files highlighted in the download section. When all looks good, click ‘Start’.
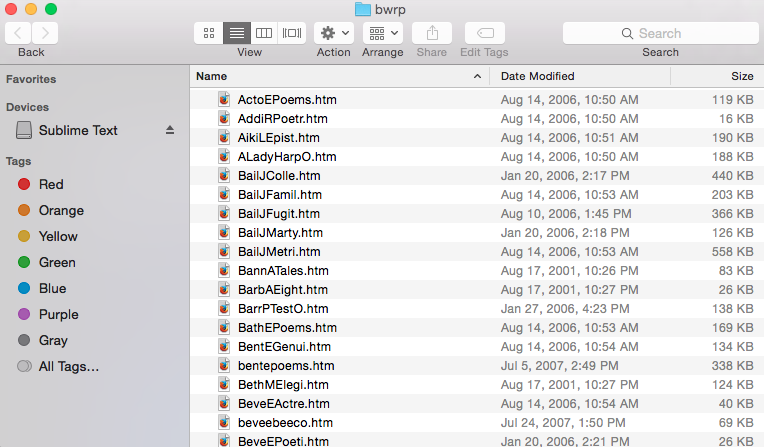
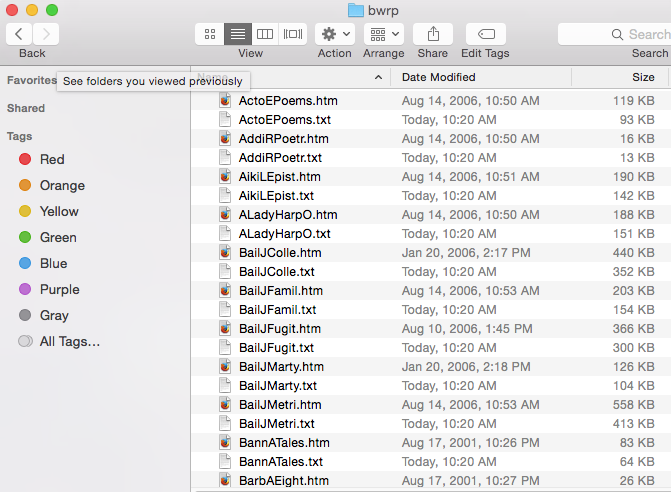
After downloading these files you’ll have a folder with 169 .htm files. Each file corresponds to a text in the collection.
Challenge 2: Making the data usable (markup removal and format conversion)
Eureka! Not so fast . . . opening one of the .htm files in the browser is misleading. If we open the .htm file in a text editor for comparison we see that there is a whole lot of markup to remove.
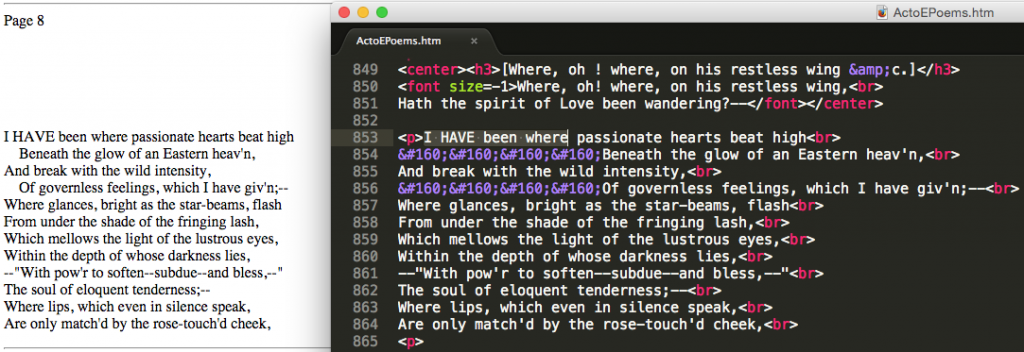
Most computers running OS X come with a small but powerful tool called Textutil. We’ll use this to iterate over every document in our collection, creating 169 .txt files stripped of markup.
– Open Terminal
– Navigate to the folder that contains the .htm files, e.g. cd/Desktop/bwrp
Convert each .htm file in the directory to a .txt file, remove markup
textutil -convert txt *.htmThis will take a bit to run, but relatively soon after we’ll have our data.
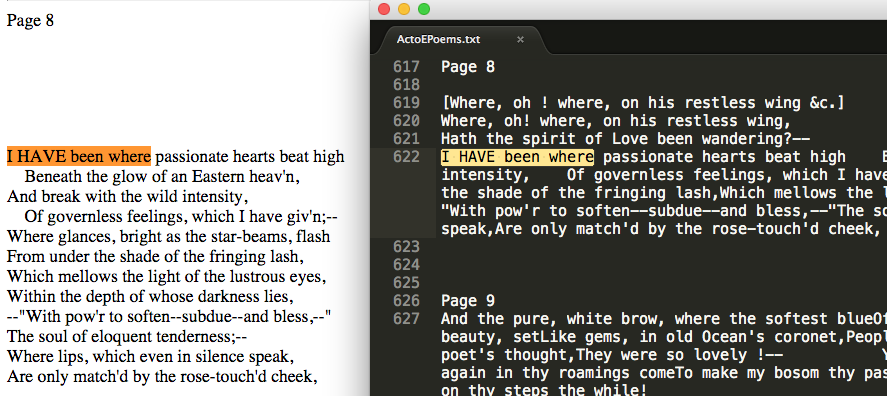
Side by side comparison shows we have successfully converted our .htm files to .txt with all markup removed.
And there you have it, an easy method to bulk download webpages, remove markup, and convert to .txt.
1 comment